
MATCHSUM 실행 가이드
MatchSum 실행 가이드
📄Paper: MatchSum(Zhong et al., 2020, ACL)
Extractive Summarization as Text Matching
💻 Github Repo
https://github.com/maszhongming/MatchSum
| PAPER | SOURCE | TYPE | SAMPLE | TRAIN SIZE | VAILD SIZE | TEST SIZE | DOCUMENT TOKEN | SUMMARY TOKEN |
|---|---|---|---|---|---|---|---|---|
| Social Media | SDS | Reddit sample data | 41675 | 645 | 645 | (average) 482.2 | (average) 28.0 | |
| XSum | News | SDS | XSum sample data | 203028 | 11273 | 11257 | (average) 430.2 | (average) 23.3 |
| CNN/DailyMail | News | SDS | CNNDM-RoBERTa sample data CNNDM-BERT sample data |
287084 | 13367 | 11489 | (average) 766.1 | (average) 58.2 |
| WikiHow | Knowledge Base | SDS | WikiHow sample data | 168126 | 6000 | 6000 | (average) 580.8 | (average) 62.6 |
| PubMed | Scientific Paper | SDS | PubMed sample data | 83233 | 4946 | 5025 | (average) 444.0 | (average) 209.5 |
| Multi-News | News | MDS | Multi-News sample data | 44972 | 5622 | 5622 | (average) 487.3 | (average) 262.0 |
SDS : Single Document Summary
MDS : Multi Document Summary
Zhong et al.의 연구에서는 CNN/DailyMail에 대해서, 2가지 버전의 전처리 데이터를 제공 (다른 데이터셋은 1개 버전)
## Dependency
pytorch==1.4.0
fastNLP==0.5.0
pyrouge==0.1.3
rouge==1.0.0
transformers==2.5.1
Download Dataset
-
CNN/DailyMail Dataset (BERT/RoBERTa ver)
├── bert # BERT에 따라 전처리 └── robert # RoBERTa에 따라 전처리 -
Other (Reddit, XSum, WikiHow, PubMed, MultiNews)
압축 해제한
*.jsonl파일을MatchSum/data경로로 이동
모델 학습
모델 저장 경로 설정
export SAVEPATH=/<trained model save path>/
모델 학습 파라미터 설정
gpus 파라미터를 통해 사용 가능한 GPU 설정
encoder 파라미터를 통해 BERT 또는 RoBERTa 모델 선택 (bert, roberta)
Zhong et al.의 실험 환경은 8개의 Tesla-V100-16G GPU를 사용하였으며, 이에 학습은 30시간 소요
메모리에 따라 다음과 같이 조정하여 훈련할 수 있다.
-
train_matching.py의batch_size또는candidate_num을 조정
batch_size(default=16)candidate_num(default=20) -
dataloader.py의max_len값 지정
class MatchSumLoader의max_len(default=180)
CUDA_VISIBLE_DEVICES=0,1 python train_matching.py --mode=train --encoder=roberta --save_path=$SAVEPATH --batch_size=8 --candidate_num=16 --gpus=0,1
모델 훈련 예시
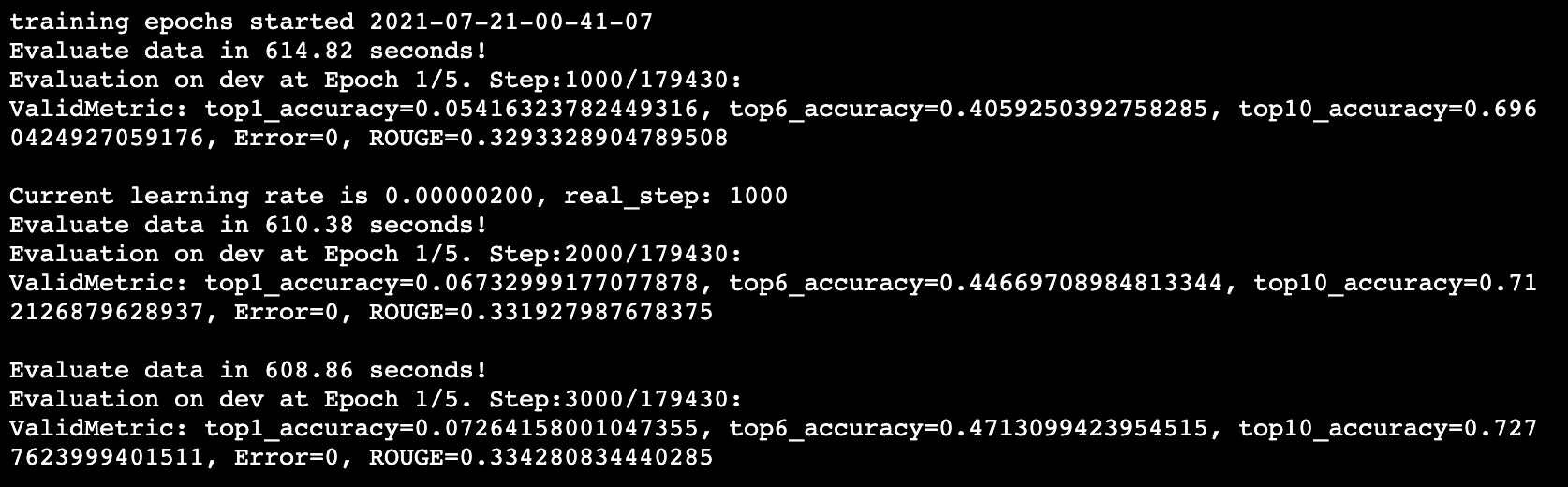
MATCHSUM(RoBERTa-base) 모델 훈련
모델 검증
학습이 끝나면 모델은 $SAVEPATH 내 모델의 학습 시작 시간 디렉토리 경로에 저장된다. (e.g. /<trained model save path>/2020-04-12-09-24-51)
모델 경로 설정
export MODELPATH=$SAVEPATH/<model training start time>
모델 테스트
📢 모델 테스트 시, GPU는 하나만 사용
CUDA_VISIBLE_DEVICES=0 python train_matching.py --mode=test --encoder=roberta --save_path=$MODELPATH --gpus=0
ROUGE 점수는 스크린에 나타나며, 학습된 모델은 $SAVEPATH/result에 저장된다
사전 학습된 모델
-
CNN/DailyMail
MatchSum_cnndm_model.zip -
Other (MultiNews, PubMed, Reddit, WikiHow, XSum)
ACL2020_other_model.zip
생성된 요약문 예시
-
CNN/DailyMail
ACL2020_output.zip -
Other (MultiNews, PubMed, Reddit, WikiHow, XSum)
ACL2020_other_output.zip