
RefSum 논문 리뷰
RefSum (Liu et al., 2021, NAACL)
📄Paper : RefSum: Refactoring Neural Summarization
기존 2-Stage Learning의 한계를 완화한 패러다임 제안
stage 간의 parameter 공유, pretrain-then-finetune → 서로 다른 모델을 상호 보완적으로 활용할 수 있음
2-Stage learning에는 아래 2가지 형태로 나뉜다.
- stacking : 서로 다른 여러 base 모델들로부터 생성된 candidate summary들을 통해 meta 모델이 최종 summary를 생성
- re-ranking : 하나의 base 모델로부터 생성된 여러 candidate summary들을 통해 meta 모델이 최종 summary 생성
💡 Contribution 정리
1. 서로 다른 모델을 사용한 2-stage learning의 한계 분석
기존 2-stage learning은 다음과 같은 한계를 가지며, 이로 인해 서로 다른 모델을 온전히 활용하기 어려움
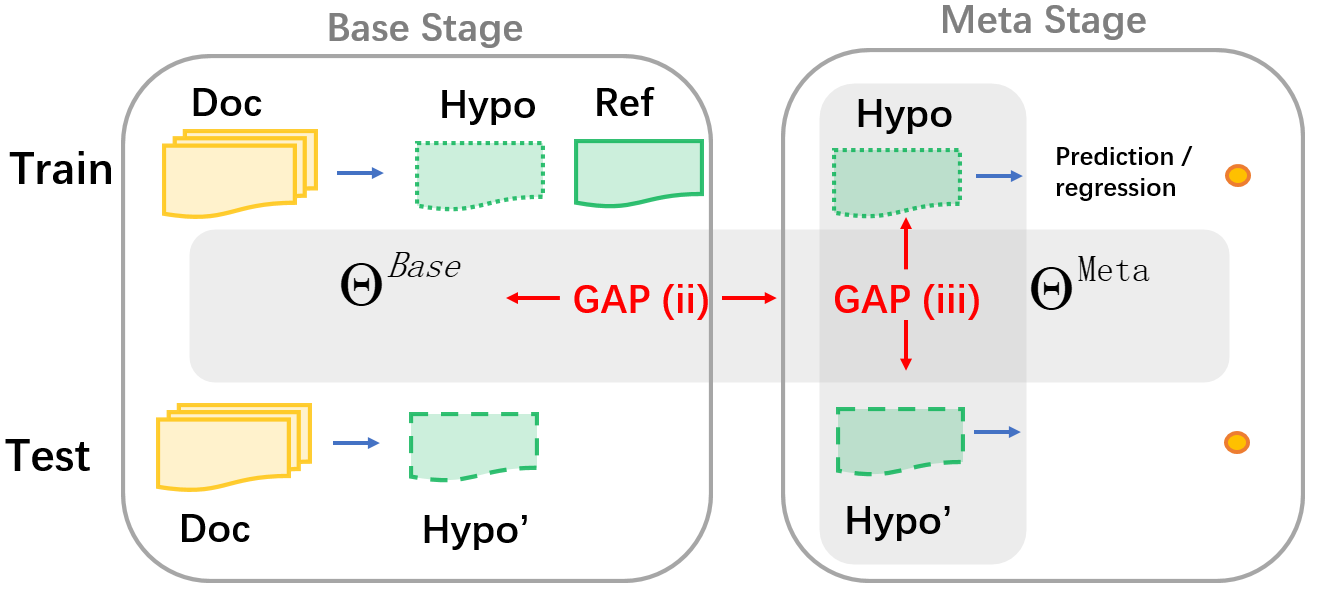
- Base-Meta Learning Gap Base model과 Meta model 간 parameter sharing의 부재로 인해 발생 → Meta model은 Base model의 output을 온전히 활용하지 못함
- Train-Test Distribution Gap 훈련 데이터에 대한 Meta model의 output distribution과 검증 데이터에 대한 output distribution은 차이가 있음 → 훈련 데이터에 대한 output distribution이 더 정확함
2. 두 Gap을 완화한 패러다임 제안
Refactor
- Base model이면서, Meta model로도 활용할 수 있어 Parameter sharing이 가능함 → Base-Meta Gap 완화
-
2번의 학습으로 다양한 candidate summary를 고려할 수 있음 → Train-Test Gap 완화
① pre-train : Input document로부터 candidate summary 생성
② fine-tune : Base model의 다양한 output으로부터 new candidate summary 생성
Refactor는 Base model과 Meta model을 분리하지 않고 공통으로 사용함으로써 parameter sharing이 가능함
기존의 2 stage learning의 분리된 base-meta 모델
\[\begin{aligned} C = BASE(D, \mathcal{T}, S, \theta^{base}) \newline C^{*} = META(D, \mathcal{C}, \theta^{meta}) \end{aligned}\]Refactor를 통해 통합된 base-meta model
\[C^{*} = REFACTOR(D,\mathcal{C}, \theta^{refactor}) \\\]아래는 Liu et al.의 실험을 요약한 내용이다.
Base : base 모델만 사용한 경우
Pre-trained : pre-trained Refactor를 meta 모델로 추가한 경우
Supervised : Refactor를 meta 모델로 추가하여 base model의 output으로만 학습한 경우
Fine-tuned : pre-trained Refactor를 meta 모델로 추가한 후, fine-tuning
1) Single System re-ranking (on CNN/DM)
base 모델 : BART/GSum
meta 모델 : pre-trained Refactor / Supervied Refactor / fine-tuned Refactor
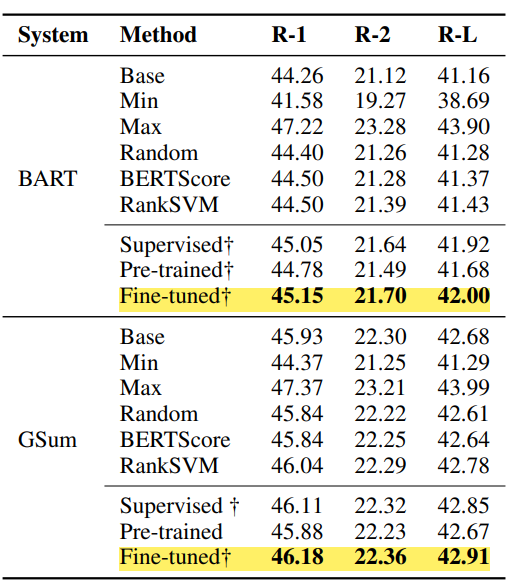
Refactor를 meta 모델로 사용했을 때, base 모델의 성능을 뛰어 넘을 수 있다.
fine-tuning이 성능을 향상시킨다.
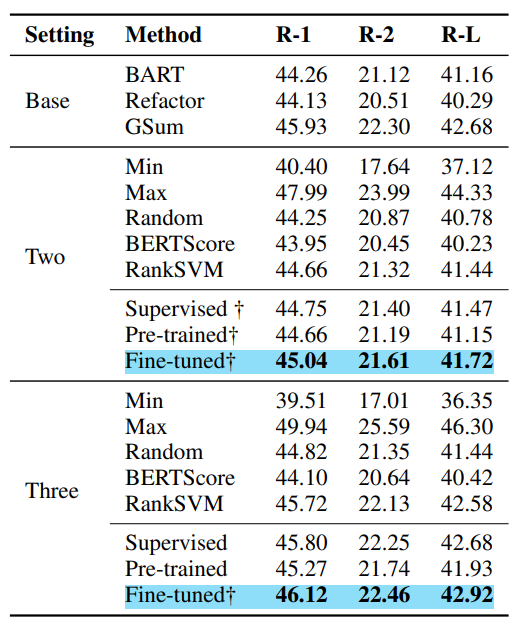
2) Multi System Stacking (on CNN/DM)
-
Summary-level combination of base model outputs
base 모델 : BART & pre-trained Refactor (Two)/ BART & GSum & pre-trained Refactor (Three)
meta 모델 : pre-trained Refactor / Supervied Refactor / fine-tuned Refactor각 base model의 output을 summary-level로 combination
-
Sentence-level combination of base model outputs
base 모델 : BART & pre-trained Refactor
meta 모델 : pre-trained Refactor / Supervied Refactor / fine-tuned Refactor각 base model의 output을 sentence-level로 combination
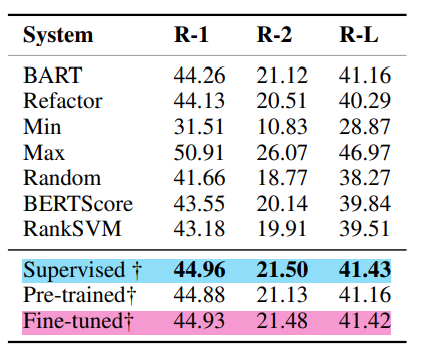
3) Generalization on 19 Top-performing System (on CNN/DM)
base 모델 : 19개의 Top-performing system
meta 모델 : pre-trained Refactor
이 실험에서 meta 모델인 pretrained Refactor는 fine-tuning 없이 base 모델의 output을 통해 summary를 추출하였다.
19개의 모델을 조합하며 multi-system stacking 실험을 수행하였고, 결론적으로 비슷한 성능을 가진 모델들이 base 모델로써 사용되었을 때 좋은 성능을 보였다.
아래 그림에서 x 축은 base 모델로 사용된 system들 사이의 성능 차이이며, ROUGE-1 score를 통해 측정되었다.
y축은 Refactor를 통한 single base model을 사용한 경우 대비 모델 성능 향상률을 의미한다.
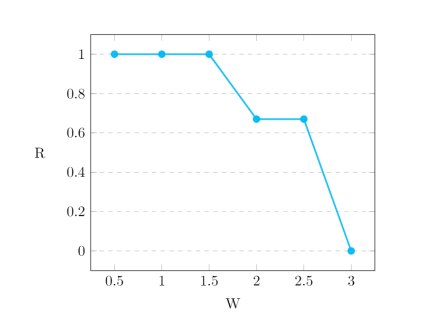
base 모델 간 성능 차이가 적을 수록 Refactor를 추가한 모델의 성능이 향상된다.
4) Effectiveness on X-Sum
base 모델 : BART, PEGASUS
meta 모델 : pre-trained Refactor / fine-tuned Refactor
실험 1 과 비슷한 결과 도출
5) Fine-grained Analysis
base 모델 : BART & pre-trained Refactor
meta 모델 : fine-tuned Refactor
두 base 모델인 BART와 pre-trained Refactor가 생성한 candidate summary의 ROUGE score 차이 (performance gap)에 따른 meta 모델의 정확도 측정
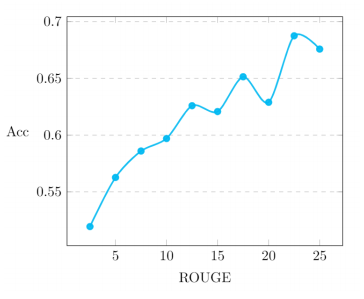
performance gap이 클수록 meta model의 정확도가 향상되는 것을 확인할 수 있다.
performance gap이 크다는 것은 어느 한 모델의 ROUGE score가 낮고 다른 모델의 ROUGE score가 높다는 것인데,
이를 통해 두 base 모델이 서로 상호보완적으로 동작하고 있음을 짐작할 수 있다.
(어느 한 모델의 ROUGE score가 계속 낮고, 다른 모델이 높은 score를 가지지 않나 생각해볼 수 있겠지만, 논문에서 제안한 것은 비슷한 성능을 가진 모델들을 base 모델로 사용하는 것이기 때문에 상호보완적으로 동작할 가능성이 높다)
논문을 읽고 이해가 가지 않는 부분이 있는데,
논문에서 Base-Meta 간 Gap이 2 stage learning 성능에 영향을 주는 주요 요인이라고 언급하였으며,
이 gap을 완화할 REFACTOR를 도입하였다.
하지만, 실험 내용을 보면 Base-Meta 간 Gap은 해결되지 않은 것으로 추정된다.
Train-Test gap은 Fine-tuning을 통해 해소될 수 있지만, Base-Meta 간 gap은 Parameter sharing을 통해 해소되어야 하는데 (논문에서 주장한 바에 의하면), 실험 내용을 보면 Refactor는 meta 모델로만 사용되는 것이 대다수 이며, 실험 2에서 Base 모델로도 사용되었지만, 이때 base 모델은 Refactor 외에도 GSum, BART도 사용되었다.
Refactor가 아닌 다른 base 모델과 meta 모델은 Parameter Sharing이 이뤄지지 않는 것으로 보이며, BART와 GSum의 output을 meta 모델이 온전히 이용한 것인지 알 수 없다.
Base-Meta간 gap을 해소하는 Parameter sharing이 성능과 어떤 연관이 있는지 밝히는 실험이 없었기 때문에, 논문의 저자이신 Yixin Liu분께 이 contribution에 대한 질문을 드렸다.
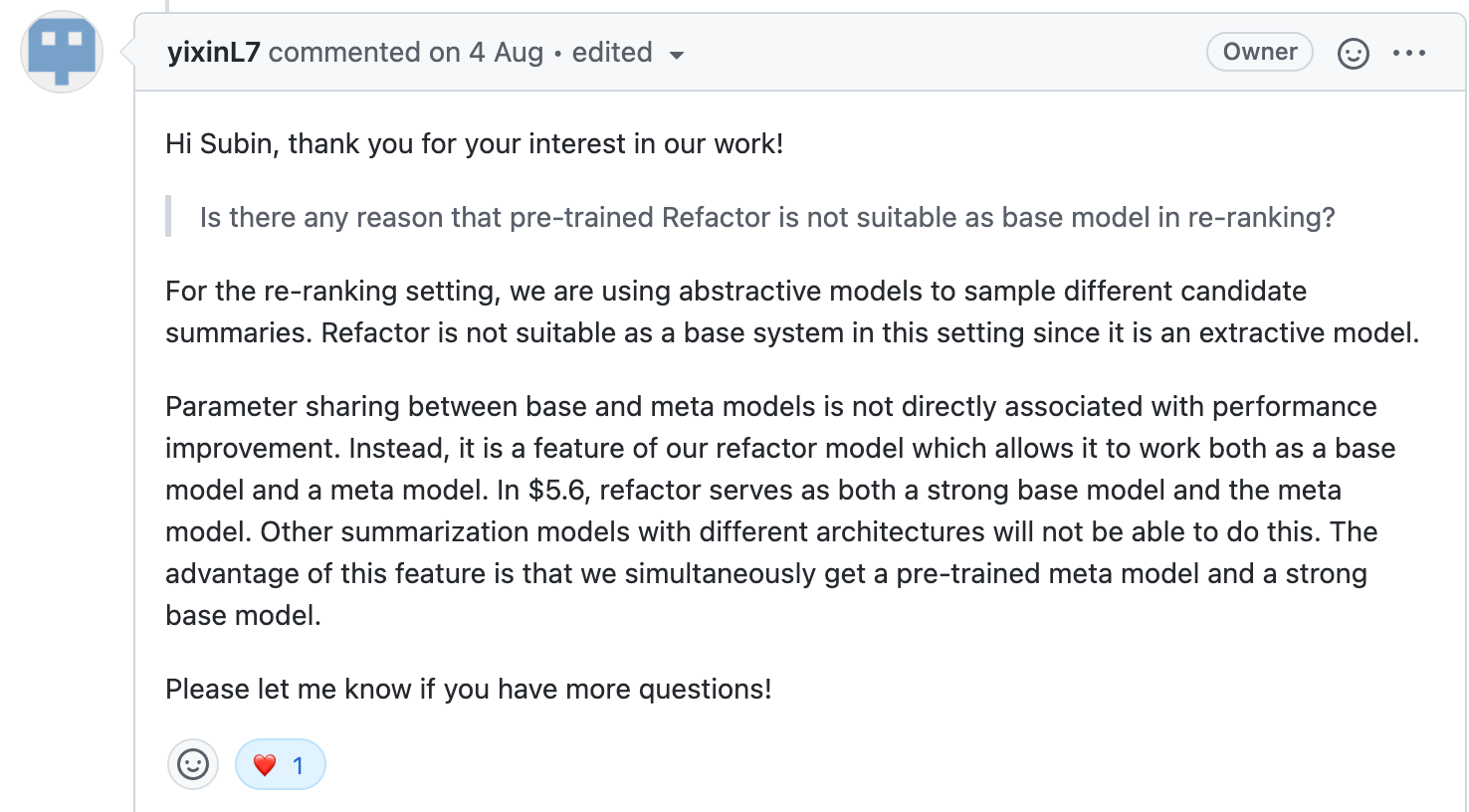
논문의 저자로부터 이에 대한 답변을 받았다.
Re-ranking task의 candidates는 추상 요약 모델로부터 생성된 추상 요약문으로 구성했기 때문에 추출 요약 모델인 Refactor를 base 모델로 사용하기 적절하지 않았고,
Parameter sharing은 논문에서 제안한 프레임워크의 특징 중 하나로, 성능 향상과 직접적인 연관은 없으나, 한번의 학습으로 pre-trained meta 모델을 얻는 동시에 base 모델을 얻을 수 있다는 장점이 있다.